Harnessing OS Principles for Multi-Agent Swarms - Enhancing agent Collaboration, Memory Management, and Security in AI

Publication Date: March 23, 2025
Author: Dheeraj Pai
If you're in business, you've probably been flooded with pitches from AI agent companies. AI agents are everywhere now—they control browsers, run command-line tools via Warp, and manage computers through OpenAI and Claude interfaces. They handle cloud infrastructure with services like Infra.new, optimize terminal operations, and integrate with codebases through tools like Cursor. They're changing how we build websites, handle customer support, boost sales, run marketing, and develop software.
Building a specialized AI agent requires several components. Take a stock trading agent that analyzes top performers and executes trades automatically.
This requires a swarm of agents with specific roles:
- We need privacy protection—agents shouldn't expose your investment account details or sell data to third parties.
- Public market data is best processed in the cloud, not locally.
- Only a trusted local LLM should have permission to execute trades—not something running on OpenAI's servers.
- Transactions above certain thresholds need your approval before execution.
- Time-sensitive analysis (like breaking news impacts) needs fast LLMs like Groq, Cerebras, or Sambanova where milliseconds count.
- Deep fundamental analysis might require powerful models like OpenAI 4.5 or O1-Pro, despite their higher cost ($600/prompt).
No single LLM can handle this entire workflow effectively.
Sometimes, time is more important; sometimes, privacy or accuracy matters. Sometimes, having a human in the loop is critical—each case has its specific use scenario.
Agent memory must be interoperable—output from one agent should feed directly into another. For collaborative work, agents need shared memory access. If Agent X discovers market insights, Agent Y should immediately access this data. This requires a shared memory system with OS-like locking mechanisms to prevent data corruption.
Agents should function like team members. If one agent is evaluating investments and another spots a time-sensitive opportunity, it should interrupt the decision process with critical input.
Security is non-negotiable. Individual agents shouldn't have system-wide access. A central "KERNEL" agent should manage permissions, similar to an OS kernel. Other agents request specific actions through this controller. This architecture should run locally when privacy matters, with human approval for critical operations.
-->> Single LLMs fail because they can't simultaneously optimize for speed, privacy, and cost. Different tasks need different capabilities, and a coordinated agent swarm delivers better results.
OS-Inspired Memory Management
Consider the example of the agent system for stock management AI that we discussed above.
We might have, for example, four different agents:
- Agent 1: A Groq agent reading news and updating insights continuously.
- Agent 2: This agent checks the portfolio and decides the best way to invest at a given point.
- Agent 3: A transaction agent that will bid/ask for a share, option, or any asset, and report if it was successful.
- Agent 4: A slow "Deep research LLM" that performs fundamental analysis and updates insights to the memory (to be fed to the Groq agent and other decision-making agents as well).

Updates from one agent might trigger updates in other agents. You want to avoid issues like race conditions. For example, if two agents read the content, produce output, and then start writing to memory, one might overwrite the other's data.
There should be some kind of locking system. Alternatively, if it's okay to run asynchronously, there should be placeholder memory for Agent 1 to write to when it completes its task.

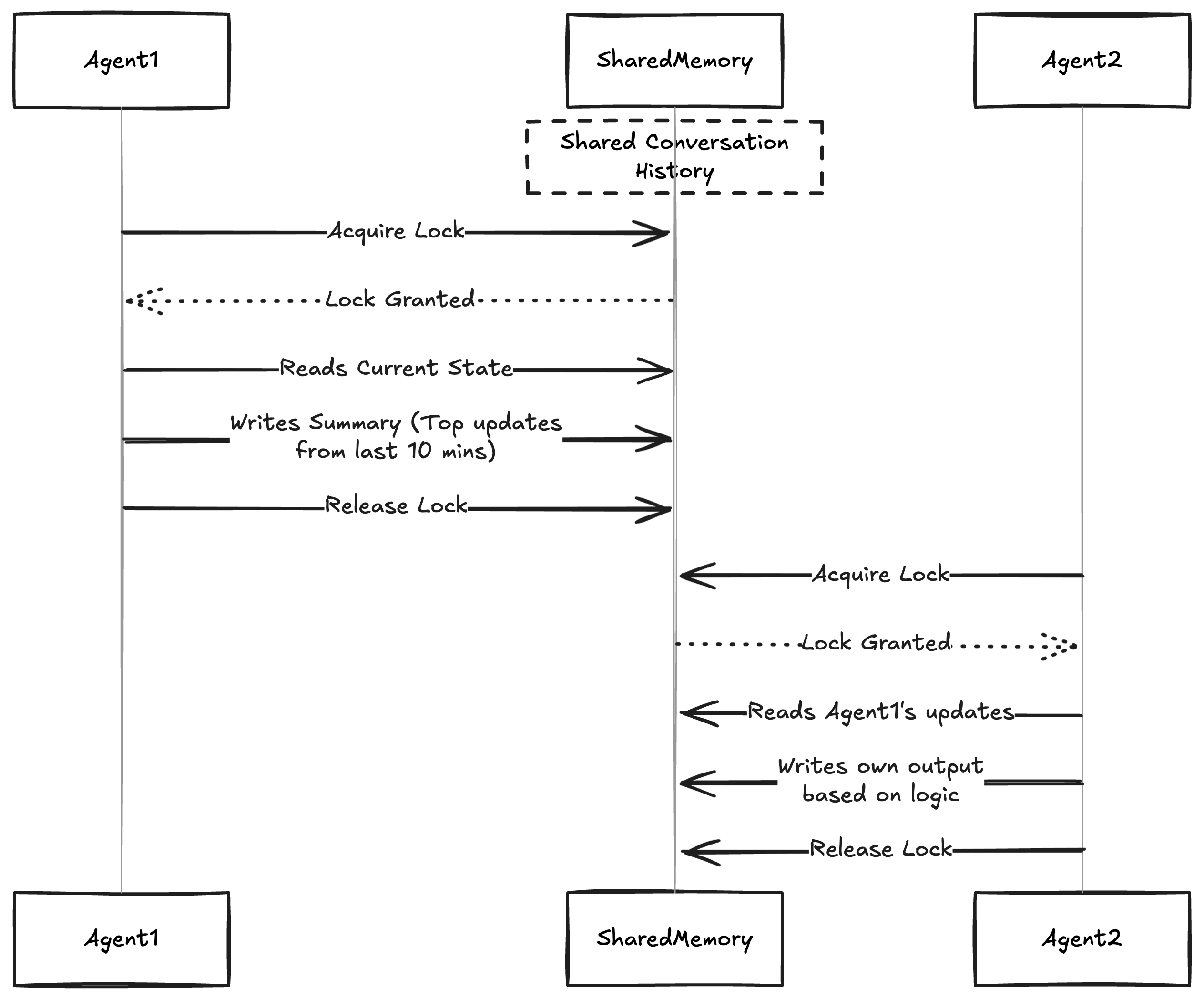
This is where short-term memory management becomes essential and very useful.
A simple example implementation would look like this:
- Agent 1 acquires a lock on the shared memory.
- Agent 1 reads the shared memory.
- Creates a placeholder for its result.
- Releases the lock.
- Agent 2 acquires a lock on the shared memory.
- Agent 2 reads the shared memory.
- Recognizes that there is something to be added by Agent 1. It decides based on logic whether to wait or continue without it, keeping a placeholder to write down the result.
- Releases the lock.
This way, Agent 1 and Agent 2 can work together efficiently.
What happens if there is no lock? Consider an example where there is an overwrite, a dependency, and an alternative where Agent 2 should wait until Agent 1 has completed its job.
-
Long-Term Persistence: Now, we have Agent 4 for deep research. It aims to perform a fundamental analysis of a particular stock, say NVDA. The agent needs to pick up specific information at random. You cannot load all the data about NVIDIA into the prompt and just send it to the LLM. The LLM must be able to select specific data. For instance, if it predicts that GPU hardware parts will be in high demand, it should quickly fetch related information. This retrieval should be fast and accurate. Among a bulk of 1 million articles about 10,000 different stocks, it should identify those relevant to a specific use case.
We need two things here:
- A retriever that will quickly retrieve memory from the database and get related content efficiently.
- Load this data into short-term memory for agents currently using it.
A quick search should be implemented—using RAG (Retrieval-Augmented Generation) and reranker graphs, embedding-based retrieval, multimodal retrievers, summary-based retrievers, and other indexed databases. These tools are essential for efficient data handling.
-
Inter-Agent Communication and Shared Memory: Fast data accessibility and shared memory among agents are vital. All data should be accessible to other agents as quickly as possible, ensuring efficient collaboration and decision-making. This shared memory system allows agents to work together seamlessly, much like OS processes using IPC (Inter-Process Communication) to share information efficiently.
The Power of Multi-Agent Swarms
Multi-agent systems parallel modern OS architecture:
- Coordinated Communication irrespective of how the agents take time to respond: Agents exchange data like OS processes use IPC. Some agents might
- Resource Sharing: Swarms distribute workloads across specialized agents, similar to how OS schedules CPU time and memory.
- Fault Tolerance: Robust agent systems isolate failures and redistribute tasks, preventing single points of failure.
Enhancing Development Collaboration
OS principles streamline AI development:
- Modular Design: Like OS components, well-designed agents are independently upgradeable, improving maintenance and scaling.
- Standard Protocols: OS-inspired communication standards ensure agents can exchange data consistently, reducing integration headaches.
- Effective Debugging: OS monitoring approaches help track distributed agent behavior and quickly identify issues.
Securing AI Through OS Concepts
OS security translates directly to AI:
- Process Isolation: Like OS sandboxing, agents need strict boundaries and authentication to prevent unauthorized access.
- Resource Controls: OS security practices like least privilege and secure memory handling protect sensitive data.
- Regular Updates: Like OS security patches, agent systems need continuous updates to address vulnerabilities.
Dynamic Loading
-
Dynamic Loading: Just as OS loads necessary modules on-demand, modern AI systems can defer loading of non-critical data until it's needed, ensuring optimal resource allocation.
Agents like Agent 2, which checks portfolios, and Agent 3, which handles transactions, benefit from dynamic loading by accessing only the data they need at the moment, thus optimizing performance.
For example, Agent 2 uses dynamic loading to access only the necessary portfolio data at the moment, allowing it to make timely investment decisions without being bogged down by irrelevant information. This ensures that the agent can quickly adapt to market changes and optimize investment strategies.
Similarly, Agent 3 benefits from dynamic loading by fetching transaction-related data on-demand. This capability allows the agent to respond swiftly to market fluctuations and execute trades efficiently, without the overhead of processing unnecessary data.
Dynamic loading is a technique commonly used in software engineering where code modules or libraries are loaded into memory at runtime as needed, instead of loading everything upfront. This concept can be effectively leveraged in AI agent architectures.
Here's how you could apply dynamic loading to AI agents practically:
-
Modular Agent Behaviors: AI agents might handle multiple specialized tasks (e.g., sales, support, analytics, QA). Dynamically load the task-specific models or skills only when the agent encounters a scenario requiring them.
-
Dynamic Agent Personalities: Customize agent personalities based on user preferences by dynamically loading personality modules at runtime.
-
On-Demand AI Capabilities: AI agents can benefit from modular capabilities like summarization, sentiment analysis, entity extraction, or translation. Dynamically load capability plugins based on the context of user interaction.
-
Resource Optimization: Large AI models consume substantial memory. Dynamically load AI models based on current demand and unload them when no longer required, significantly optimizing resource usage.
-
Plugin Ecosystem: Create a self-serve platform allowing users to add custom behaviors to their AI agents. Allow users to add plugins that the platform dynamically discovers and loads at runtime.
The concept of dynamic agent loading and execution is crucial. Every agent does not need to know everything in advance. For example, an AI agent performing stock analysis might need portfolio details only when predicting stock movement. Personal portfolio data is irrelevant to the market but crucial for risk calculation. If a human in the loop needs a graph for decision-making, the main agent doesn't need to create the graph itself. Instead, it can perform analysis on the main data and rely on subsequent LLMs to update content with internal portfolio data and calculate risk. This is akin to tool calling, where Agent X is dynamically loaded into the output of Agent Y.
-
Advantages
-
Scalability: Dynamic loading enables the scalability of AI systems, allowing for the deployment of thousands of agents if required. For example, in stock market analysis, agents can analyze over 1000 stocks while considering the context of other stocks, demonstrating the system's ability to scale without explicitly determining the best stock.
-
Development Speed: Dynamic loading contributes to faster development by providing a structured way to handle long contexts. It allows for deferring predictions and completions to other LLMs, streamlining the development process and enhancing efficiency.
-
Privacy Management: This approach helps manage privacy by ensuring that useful outputs are provided without compromising accuracy. Dynamic loading allows for selective data access, maintaining privacy while delivering precise results.